
Using GitHub Classroom
Published:
There is always a tension in academia, particularly in computer science, between teaching the theory and teaching the practice. Theoretical computer science is largely mathematical; practical computer science… isn’t.
One way to think about the difference, is that the theory in computer science is all about abstractions whereas the practice is down to brass tacks.
Brass tack #1 : source control
The artefact that many professional computer science graduates produce is source code. Because of the complexity of coding, a programmer, even a seasoned one, can take several attempts to get something right. This means going down blind alleys, making mistakes, and taking two steps forward and one step backwards.
The key tool being able to recover from that one step backwards is source control.
Source control allows a coder to take a snapshot of their codebase, and to be able to revert to that snapshot. Source control allows several people to work on the same codebase at once, without stepping on each other’s toes too often. Source control allows the released code to be patched for a quick “release to production” while the next version of the program is being worked on — without the new, untested, features also being pushed on unsuspecting users.
Git
There are many different source control programs around. The one I’m going to get the students to use in my Data Structures course is git.
The reason I’m choosing git for the students is because that’s what I’m currently most familiar with, and currently git’s market share in open source projects is 72%, making it by far the most popular in the open source community.
Distributed source control
I’ve used source control for a long time. Back when I was writing my masters thesis, I used rcs (revision control system). I used it for keeping copies of my LaTeX files and associated diagrams. The trouble with rcs is that there was only one copy of the repository (history), unless you copied it to another computer.
More modern systems use a central server to keep an off-machine copy of the source code.
Distributed version control systems such as git or Mercurial go one step further and allow every developer to have a complete copy of the repository on their machines. They also allow more than one remote “central” server. Hence, the code is distributed among many copies.
This makes the system much more robust to file system outages or disk crashes.
GitHub
There are several operators of remote git repositories. GitHub and Bitbucket are two. I’ve used both for personal and professional projects. More recently, I’ve migrated my work to GitHub because they relatively recently allowed more use of private repositories (those that cannot be seen by others).
Data structures use of git
To help the students become familiar with git, I’m going to distribute all of my programming assignments via git. That should help students come to grips with source control early (most are sophomore students).
Brass tack #2 : continuous integration
Another practice (“brass tack”) that is used in industry, but I haven’t seen much in academia is the practice of continuous integration. This is the practice of continuously sharing in-flight code, and testing that code as it is being developed.
GitHub Actions
In GitHub, it’s possible to automate things happening, like testing, when a commit is made using Actions. This means you can automatically :
- Build the software.
- Deploy the software to the test environment.
- Test the software.
- Alert the developers of any test failures.
- Deploy the software to the production environment if there are no test failures.
Sometimes (often?) that last step is only ever done manually, just in case there’s something that cannot be automated or if it would create an unacceptable outage during deployment.
GitHub Classroom
Within GitHub is a thing called Classroom. This allows me to set up assignments in git and to have those assignments auto-graded. This auto-grading is a form of continuous integration.
Automated tests
The way it works is that it allows me to add different types of testing to each assignment.
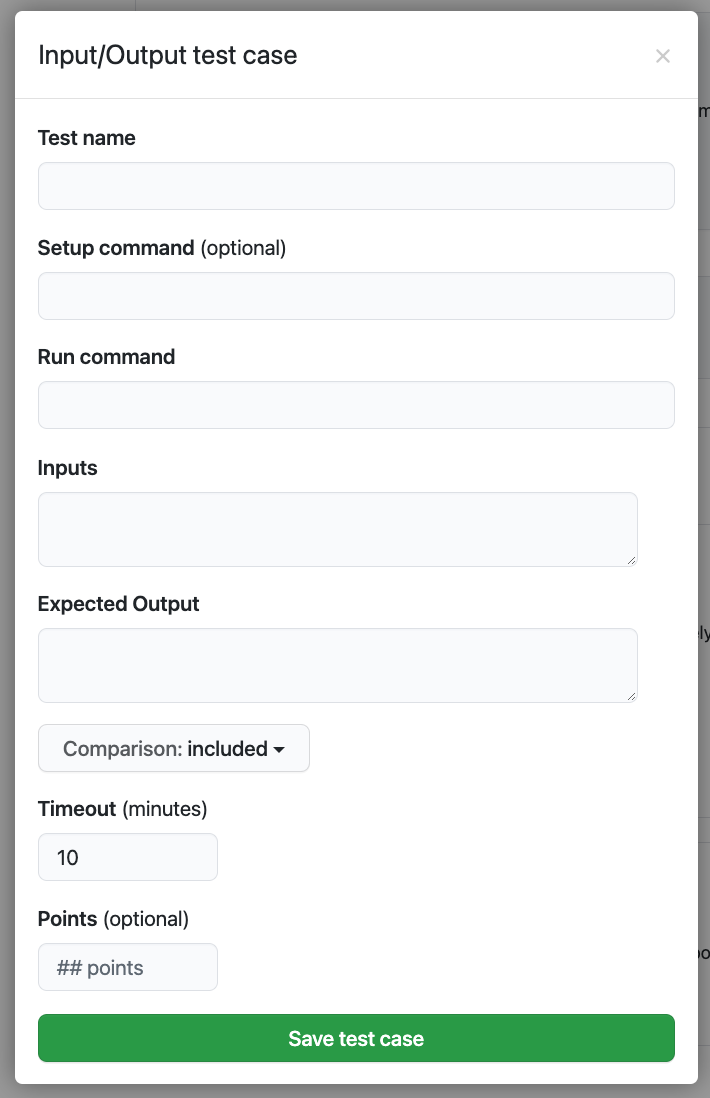
For example, most of the tests I’ve written to date use the Input-Output option shown below.
When a student submits an assignment (commits the code and pushes it to GitHub Classroom), the test Action is triggered. If all the test pass, then the output given is as below.

If any tests fail, then which test failed is indicated in the output.
Data structures use of continuous integration
While this isn’t quite the sequence noted above, this should get the students used to pushing code to the repository, and dealing with any failed test cases.
Outcome
I’m hopeful that use of git and autograding will get the students used to working with repositories. That way, when they tackle larger programming problems in teams in later years, they’ll already have some familiarity with the tools.